Exploratory Data Analysis
Python을 통해 탐색적 자료분석을 할 때, 무엇을 해야하고, 순서는 어떻게 해야하는지 막막한 경우가 많은데요. 탐색적 자료분석의 기본은 바로 변수 별로 분포를 그려보는 것이겠죠. 수치형 데이터의 경우는 히스토그램을, 명목형 데이터의 경우는 빈도표를 통해 데이터의 분포를 살펴보게 됩니다. 본 포스팅에서는 파이썬을 통해 탐색적 자료 분석을 하는 방법을 유명한 데이터셋인 타이타닉 데이터를 통하여 차근차근 알아보겠습니다.
기본적인 탐색적 자료 분석의 순서는 아래와 같이 정리해보았습니다.
1. 데이터를 임포트하여 메모리에 올린다.
2. 데이터의 모양을 확인 한다.
3. 데이터의 타입을 확인한다.
4. 데이터의 Null 값을 체크한다.
5. 종속변수의 분포를 살펴본다.
6. 독립변수 - 명목형 변수의 분포를 살펴본다.
7. 독립변수 - 수치형 변수의 분포를 살펴본다.
8. 수치형, 명목형 변수간의 관계를 파악한다.
1. 데이터 임포트.
아래와 같이 패키지와 데이터를 임포트합니다. numpy, pandas, matplotlib, seaborn은 이 4가지의 패키지는 파이썬을 통한 EDA에서 거의 필수적으로 사용하는 라이브러리입니다.

2. 데이터 모양 확인.
head(), shape, tail 등을 활용하여 데이터 모양을 확인한다.

3. 데이터의 타입을 체크한다.

데이터의 타입을 체크하는 이유는 해당 변수의 타입을 제대로 맞추어주기 위해서입니다. 범주형 변수의 경우 object 또는 string, 수치형 변수의 경우 int64 혹은 float 64로 맞추어주면 됩니다. 범주형 변수의 경우 값이 문자열로 들어가 있으면 알아서 object 타입이 되지만, 만약의 숫자로된 범주형 변수의 경우 int64 등으로 잘못 타입이 들어가 있는 경우가 있습니다.
4. 데이터의 Null 값을 체크한다.
Null Check도 매우 중요한 작업 중 하나입니다. 단순히 Tutorial이나 학습을 위해 제작된 데이터셋이아닌 현실의 데이터셋의 경우, 많은 부분이 Null 인 경우가 많습니다. 따라서 이 Null 값을 어떻게 처리하느냐가 매우 중요합니다.
Cabin 변수가 687 행이 missing이고 Embarked가 2개의 행이 missing인 것을 확인하였습니다.
Null 값이 있는 경우, 크게 그 값을 빼고 하는지, 혹은 결측치를 대치하는지 2개의 방법으로 나눌 수 있습니다. 각각의 방법에 대한 이름이 다르긴한데 보통 첫 번째 방법을 complete data analysis, 두 번째 방법을 Imputation이라고 이름 붙입니다.

위 명령어를 통해 전체의 몇 %가 missing 인지를 확인할 수 있습니다.
5. 종속변수 체크.

저는 bar_chart 함수를 만들어 종속 변수인 Survived의 유무를 다른 변수와 바로 비교 가능하도록 했습니다. 다른 방법으로는 기본적으로 종속변수의 분포를 살펴볼수 있습니다. (종속변수란 다른 변수들의 관계를 주로 추론하고, 최종적으로는 예측하고자 하는 변수입니다.)

6. 명목형 변수의 분포 살피기.
단변수 확인 및 이변수 탐색
저는 주로 단변수를 확인할때, info()를 활용하는 편입니다 하지만 보다 쉽게 보기를 원하신다면, 먼저 명목형 변수의 형을 object로 모두 변경하고 컬럼 중에서 object 타입을 가진 컬럼만 뽑아서 명목형 변수의 리스트를 만듭니다.

이 때, 데이터의 기본키(인덱스), 종속변수 등을 제외하고 분석하는 것이 좋습니다.

다음으로는 그래프를 통해 명목형 변수의 분포를 살펴보는 것입니다. 저는 5번 종속변수를 확인할때 종속변수와 다른 변수를 확인하기 위해 이미 함수를 만들어 놓았었습니다. 위와 같은 이미지 입니다 ^^;; 따라서 'Cobin', 'Sex' , 'Ticket' , 'Name' 등과 비교하여 확인하시면 됩니다



이렇게 살펴봄으로써 명목형 변수를 어떻게 다룰지를 판단할 수 있습니다. 예를 들어, 카테고리수가 너무 많고, 종속변수와 별로 관련이 없어보이는 독립 변수들은 빼고 분석하는 것이 나을 수도 있습니다.
이변수 탐색은 위에서 생존과 사망을 나누어 각각의 변수와 비교하는 것을 말합니다. 즉 성별-생존의 관계 파악처럼 두 변수의 관계를 파악하기 위해서는 위와 같이 확인할 수 있습니다.
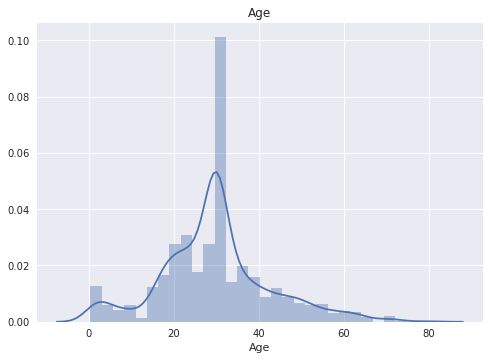
7. 수치형 변수의 분포 살펴보기
단변수 탐색
단변수 탐색은 seaborn 패키지의 distplot 함수를 이용하면 매우 편합니다.
우선 이와 같이 전체 변수 중에서 범주형 변수와 기타 인덱스 변수, 종속변수들을 제외하고 수치형 변수만 골라냅니다.


이변수, 삼변수 탐색
seaborn 패키지의 pairplot을 통해 종속변수를 포함한 3개의 변수를 한 번에 볼 수 있도록 플로팅합니다.
8. 수치형, 명목형 변수 간의 관계 탐색
앞서서 수치형-수치형 간의 관계, 그리고 명목형-명목형 간의 관계에 종속변수까지 포함해서 보았습니다. 이 번에는 수치형-명목형 간의 관계를 파악해 보는 것입니다. 예를 들어, 성별, 나이, 생존여부 3개의 변수를 동시에 탐색하고 싶을 수 있습니다. 이 경우에 명목형 변수에 따라 수치형변수의 boxplot을 그려봄으로써 대략적인 데이터의 형태를 살펴볼 수 있습니다.
참고: https://3months.tistory.com/325 [Deep Play]
'Data Analysis & ML' 카테고리의 다른 글
| Machine Learning - 언더 샘플링과 오버 샘플링 (0) | 2020.07.31 |
|---|---|
| 데이터 분석의 유형 6가지 (0) | 2020.05.16 |
| pandas.DataFrame(1) (0) | 2020.04.24 |
| Jupyter notebook - %matplotlib inline (0) | 2020.03.02 |
| Python 데이터 시각화 - 참고 사이트 (1) | 2020.03.01 |